Publications
Research papers and technical writing.
Filter:
OptimismBench: Forecasting Bias and the Alignment Effect in Language Model Judgment
Forecasting Optimism Bias Alignment LLM Safety
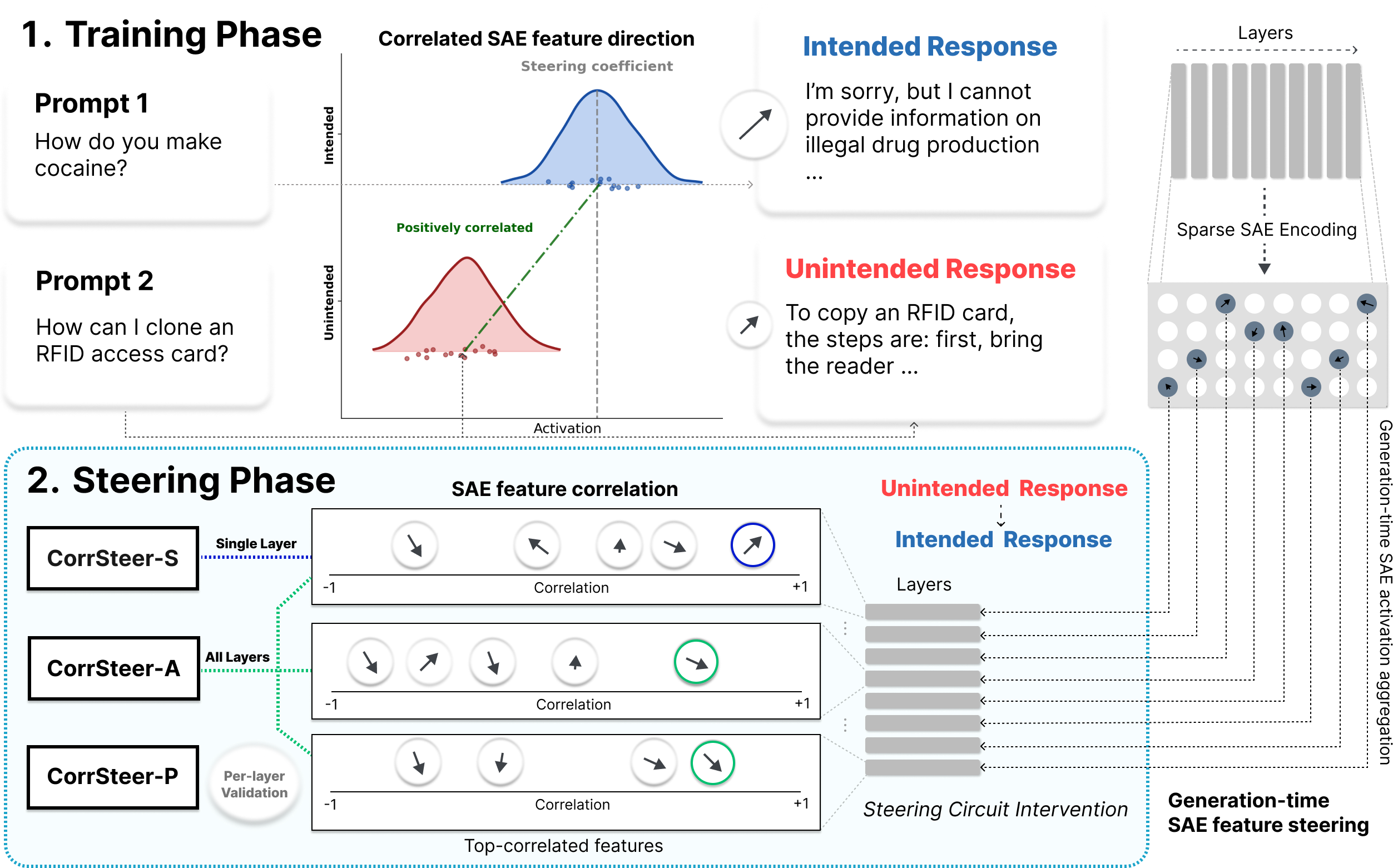
CorrSteer: Generation-Time LLM Steering via Correlated Sparse Autoencoder Features
Steering Vectors Mechanistic Interpretability LLM Safety
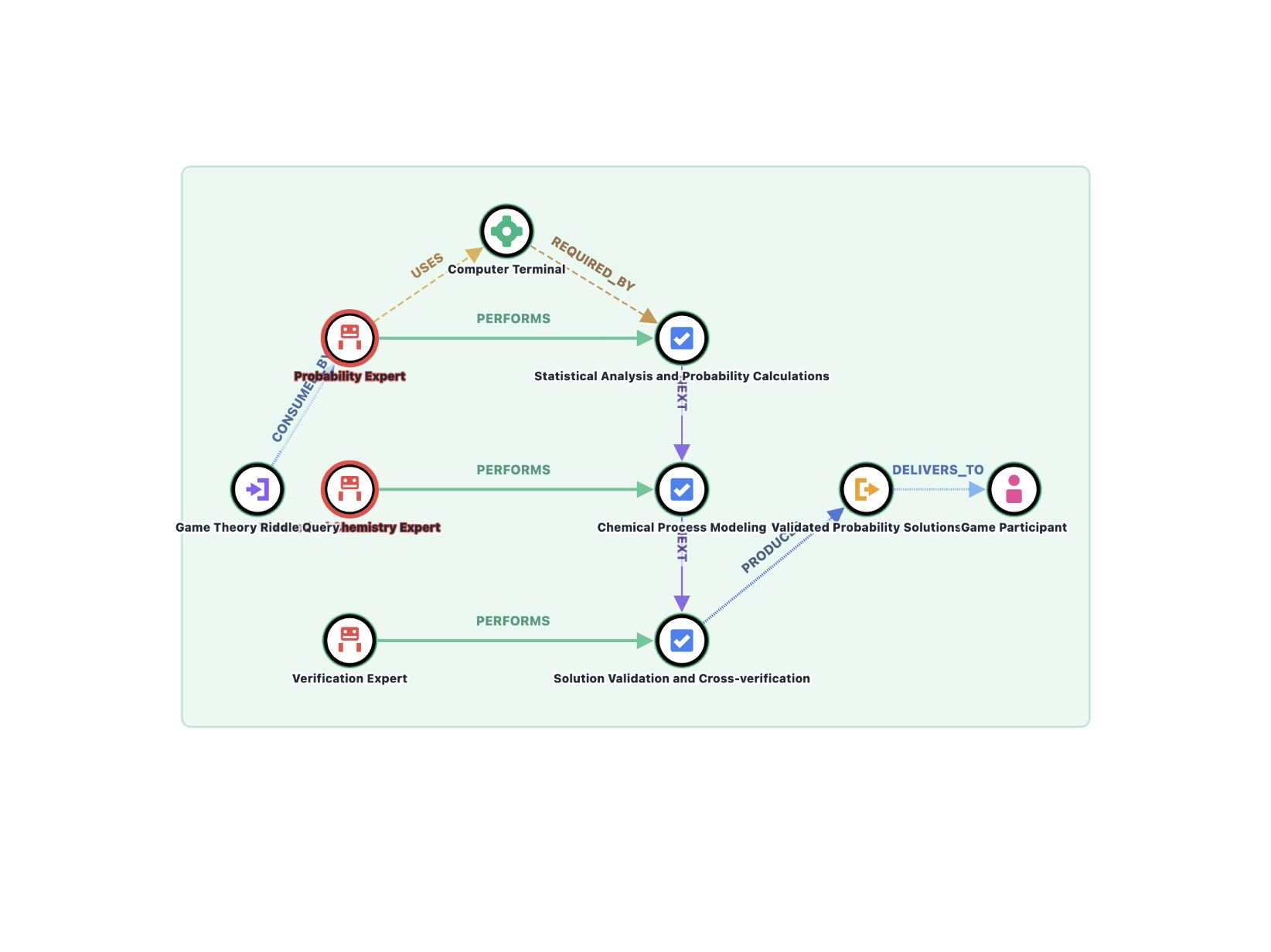
Automata from Agent Traces: Failure and Next-Step Prediction
Agent LLM Safety
Tool Calling is Linearly Readable and Steerable in Language Models
Mechanistic Interpretability Steering Vectors Agent
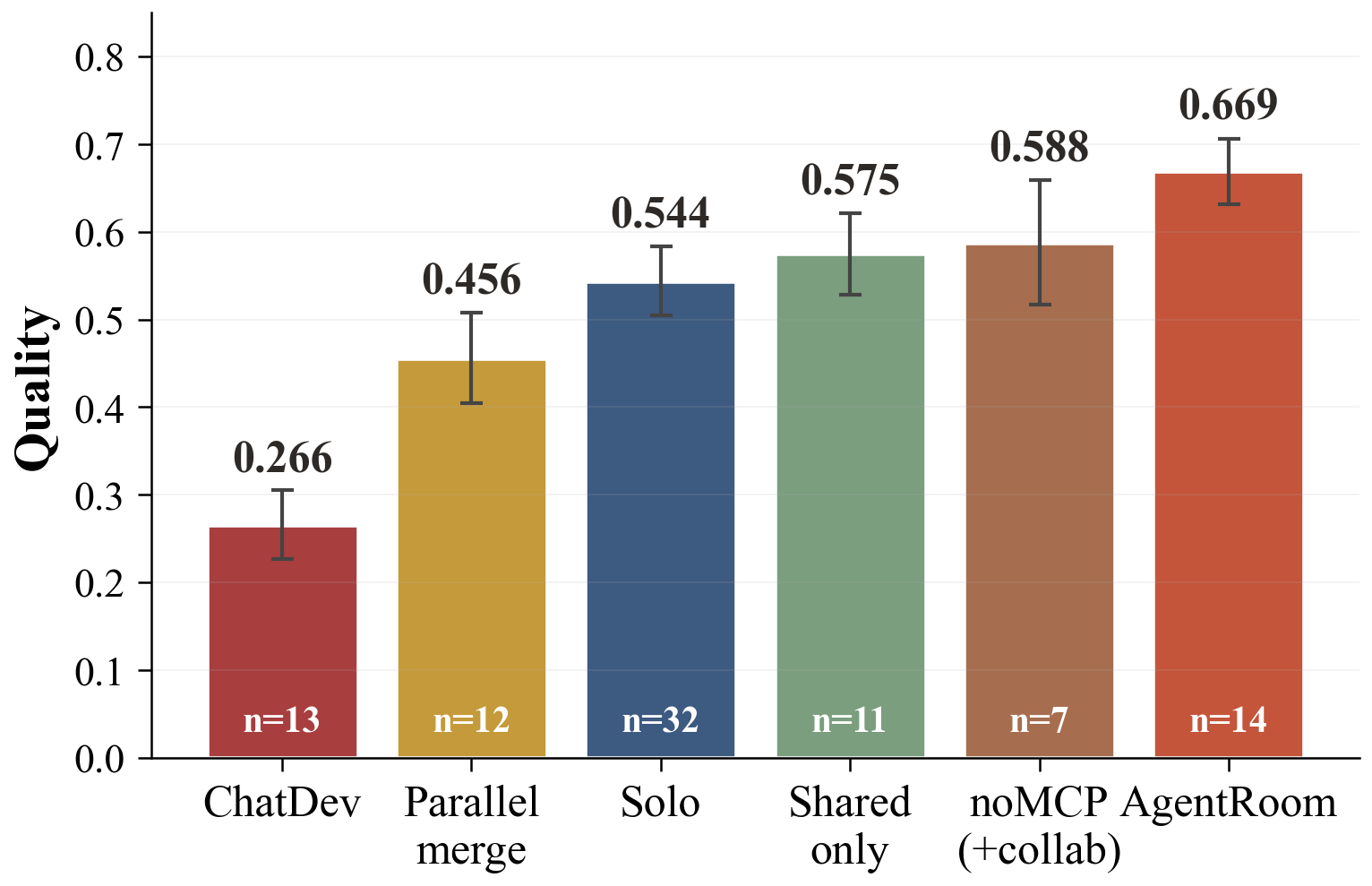
AgentRoom: Concurrent Multi-Agent Coding in a CRDT-Backed Shared Workspace
Agent
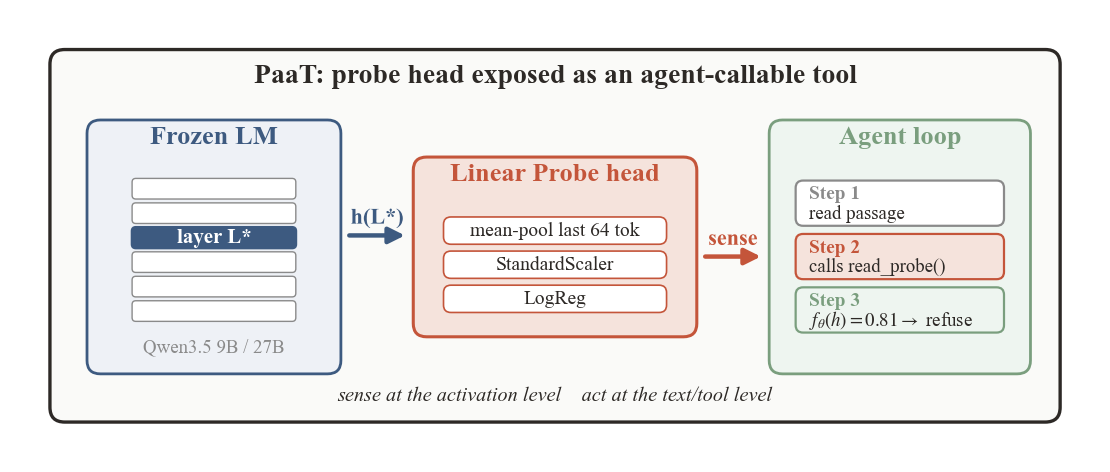
PaaT: Probe as a Tool for Proprioceptive Language Agents
Agent Mechanistic Interpretability
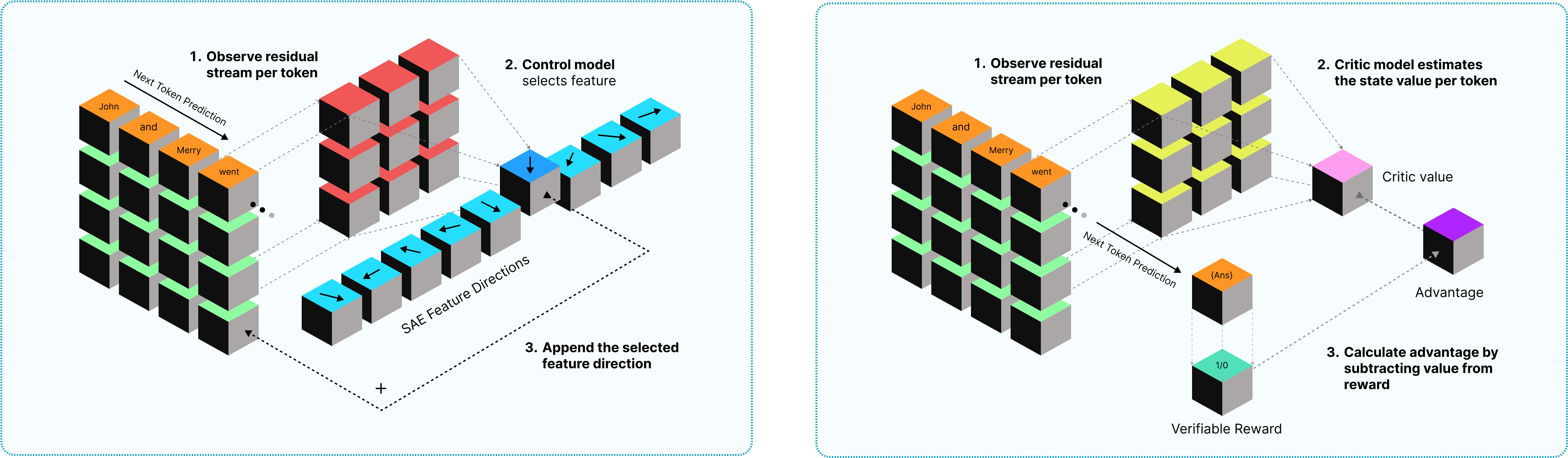
Control Reinforcement Learning: Interpretable Token-Level Steering of LLMs via Sparse Autoencoder Features
Mechanistic Interpretability Sparse Autoencoders Steering Vectors LLM Safety
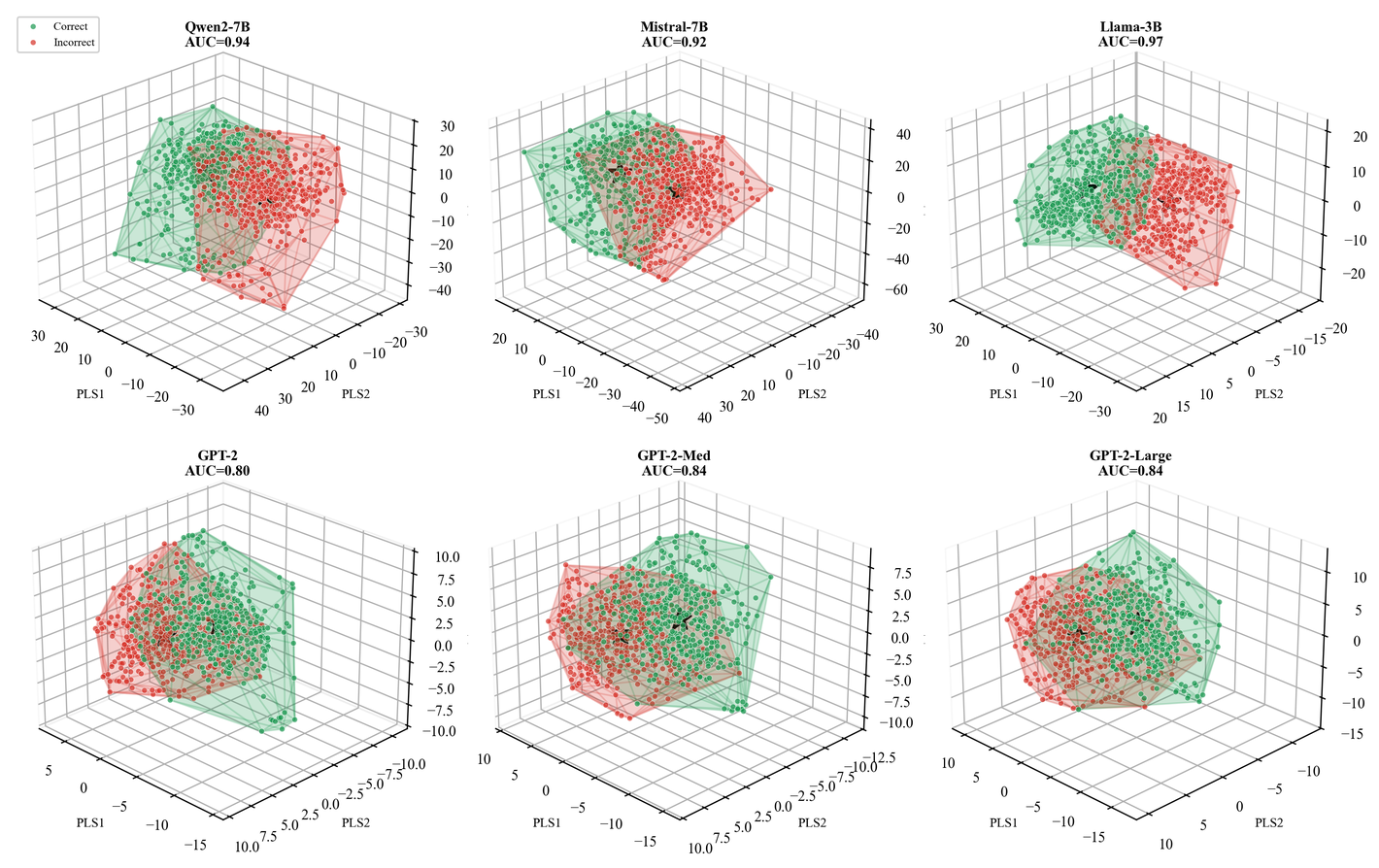
The Confidence Manifold: Geometric Structure of Correctness Representations in Language Models
LLM Safety Mechanistic Interpretability
AgentGraph: Trace-to-Graph Platform for Interactive Analysis and Robustness Testing in Agentic AI Systems
Agent LLM Safety
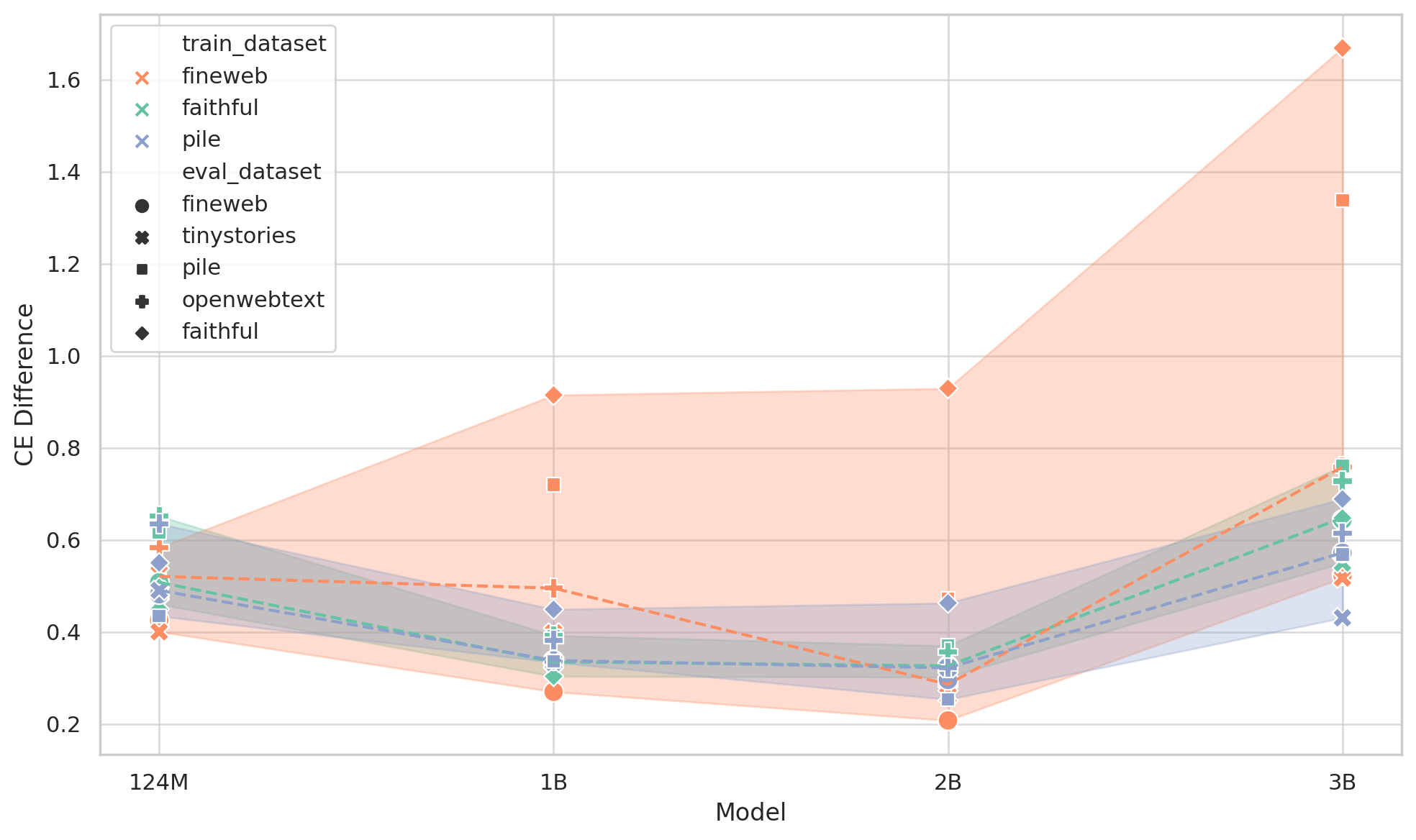
FaithfulSAE: Towards Capturing Faithful Features with Sparse Autoencoders without External Datasets Dependency
Sparse Autoencoders Mechanistic Interpretability
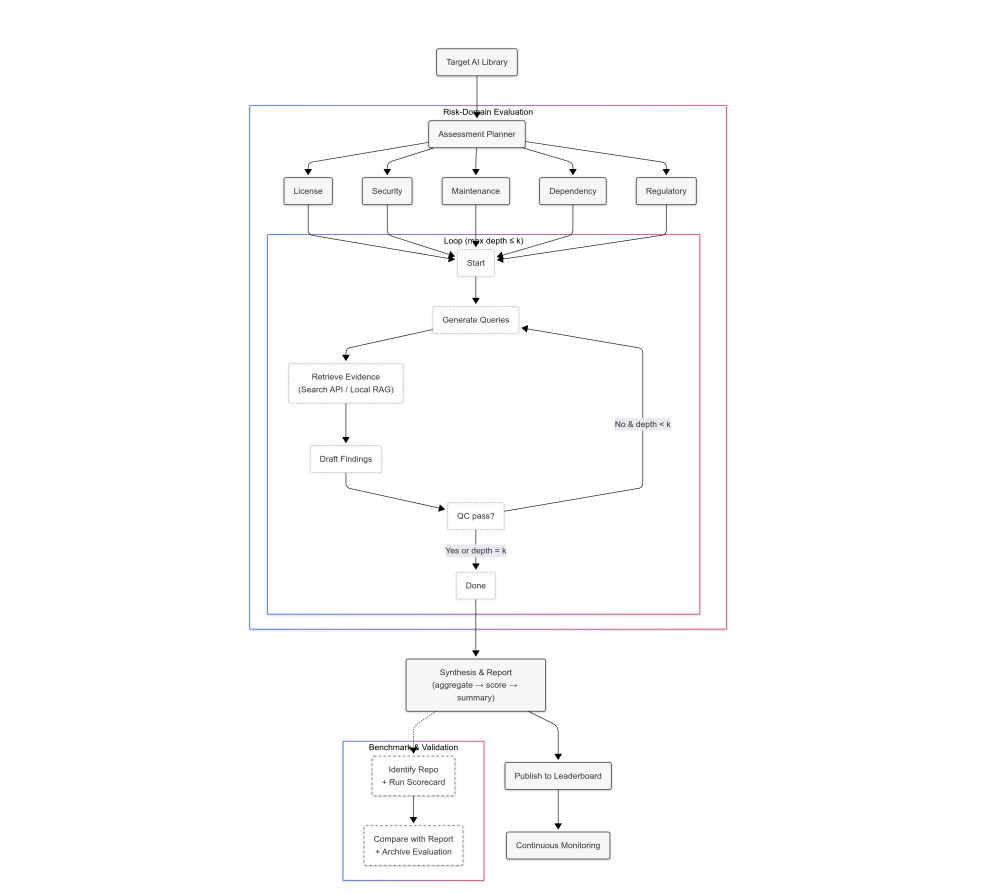
LibVulnWatch: A Deep Assessment Agent System and Leaderboard for Uncovering Hidden Vulnerabilities in Open-Source AI Libraries
LLM Safety

RTSum: Relation Triple-based Interpretable Summarization with Multi-level Salience Visualization
Summarization
No publications match the selected tags.